
- by Team Handson
- September 28, 2022
Data Science Interview Questions, Part -2
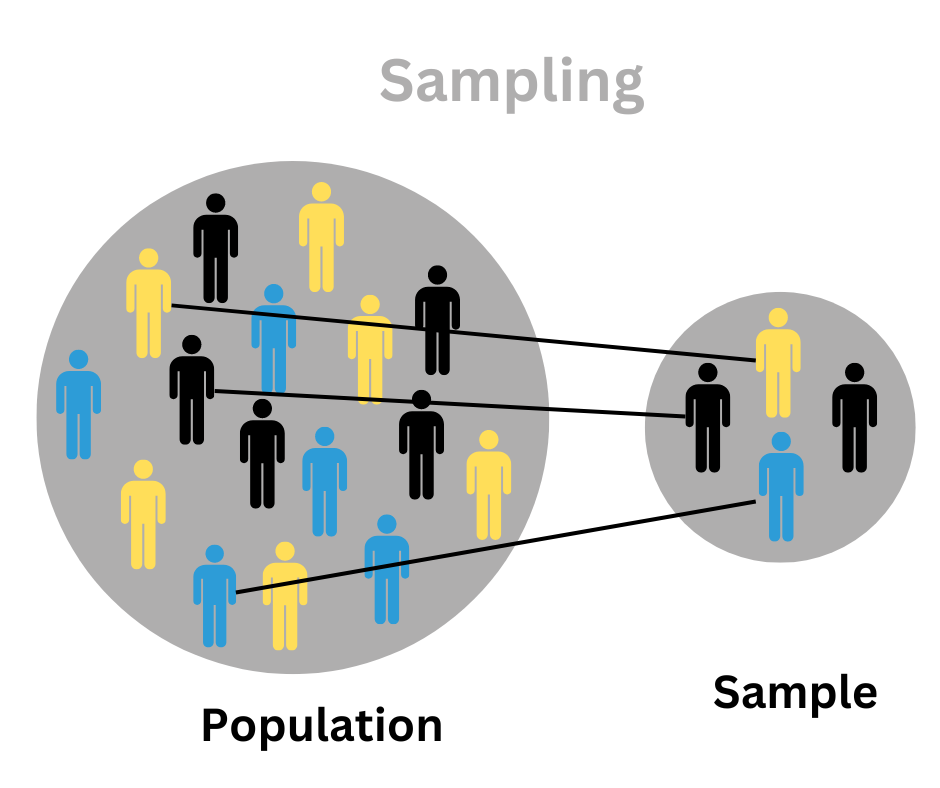
1. Discuss about the technique of sampling and its advantage?
If there is a large volume of a data set then the process of data analytical process cannot be successfully completed in one time. Therefore it is very important to find some data set that can be used to render the entire population and then work on it. During the process, it is very important to take every sample data very consciously among the huge set of data which will represent the entire data set.
Two major classifications of the data sampling based on the use of statistics are:
Probability Sampling Techniques: Stratified Sampling, Clustered Sampling, Simple random sampling.
Non Probability Sampling Techniques: Convenience Sampling, Quota Sampling, Snowball Sampling.
2. What do you mean by the terms KPI, lift, model fitting, robustness and DOE?
KPI: Key Performance Indicator or KPI measures indicate the process how the business is attaining to its goal.
Lift: A targeted measure is compared to a random choice model according to its performance. This shows a comparison that about the performance of the model versus performance without any model.
Model fitting: This shows the observation of how a model is performing.
Robustness: This shows the differences and the variances effectively of the system.
DOE: Design of Experiments or DOE is the representation of designing and to explain the variation of information under the hypothesis to throw back variables.
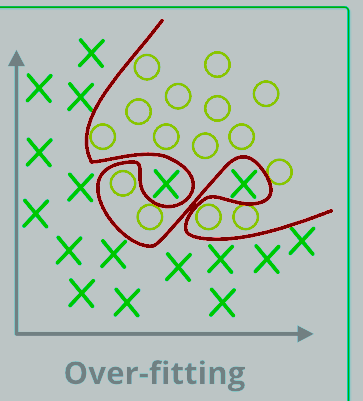
3. What are the conditions for over fitting and under fitting?
Over fitting:
The best performance of the mode depends on the sample training of data. Whether there is a new data entered as an input to the model, then no output is expected as well. Such conditions also depend on low bias and high variance in the model. Decision trees are much more tends to over fitting.
Under fitting:
In this model the relationship between the correct data cannot be spotted out due to the simplicity of the model, even its performance is not praiseworthy during the test of the data. The reason behind this is the low variance and high bias. Linear regression is very much tends to under fitting.
4. Discuss about the impact of Dimensionality reduction?
The process of Dimensionality Reduction lessens the number of attributes in a dataset to prevent over fitting. There are four predominant advantages in this process:
- Through this process the storage takes minimum space and time for the implementation of the model.
- Improves the parameter interpretation of the ML model while removing the issue of multi-co linearity.
- The process of data visualization gets easier due to the reduced dimensions.
- Ignores the steam of increased dimensionality.
5. What is the identification of a coin bias?
There is a hypothetical test for the identification process:
In the null hypothesis it is said that if the chances of heal flipping of a coin is 50% then only the coin is unbiased. And if the probability of head is not equals to 50% ten it is obviously a biased coin. The steps of the identification are:
- Flipping of the coin for 500 times
- Calculation of the P value
- Comparison of the P value against alpha and that two processes are:
If P value IS > alpha then the null hypothesis captures the data well and the coin remains unbiased.
If the P value is < alpha then the null hypothesis is abandoned and the coin becomes biased.
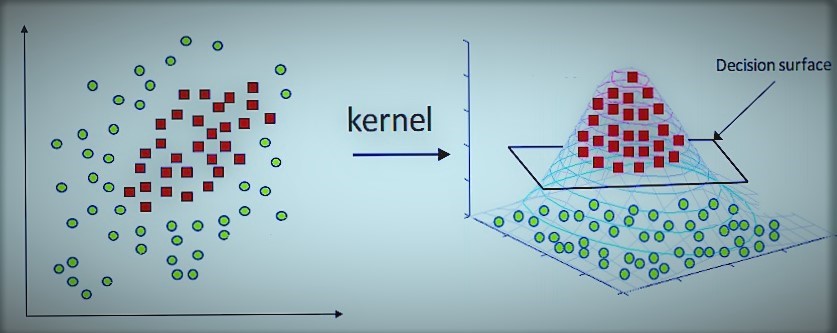
6. What is Kernel trick?
Kernel trick is a concept or a process through which the classification or the separation of the data becomes very easy. This process becomes faster when the data cannot be linearly separable. This imprecise dot product functions which are used to calculate dot products of the vectors xx and yy in a high dimensional space. This method solves a non-linear problem with the help of a linear classifier that alters linearly inseparable data into the separable one in a high dimension.
7. Discuss about the feature selection method for selecting the right variables for building efficient predictive model
In data science or machine learning algorithms it occurs to a data set. Ordinal variables are identical to categorical variables with exact and clear ordering defines. So, if the variable is supposed to be ordinal and the treatment of the categorical value will be better predictive models as a continuous variable.
8. Discus about the 3 top technical skills of Data Science.
Top three skills of data science are Mathematics, machine learning and programming etc.
- Mathematics: Mathematics is the base of data science and every data scientist should have a strong mathematical background before entering in the field of data science.
- Machine Learning and Deep Learning: If somebody is interested in the field of data science then the knowledge of machine learning and artificial intelligence is a must. A skillful rendition of the techniques like deep learning and machine learning will help to complete a good project.
- Programming: Programming is the most useful skill in the field of data science. Programming is such an ability to solve complex problems with the industry understandable code.
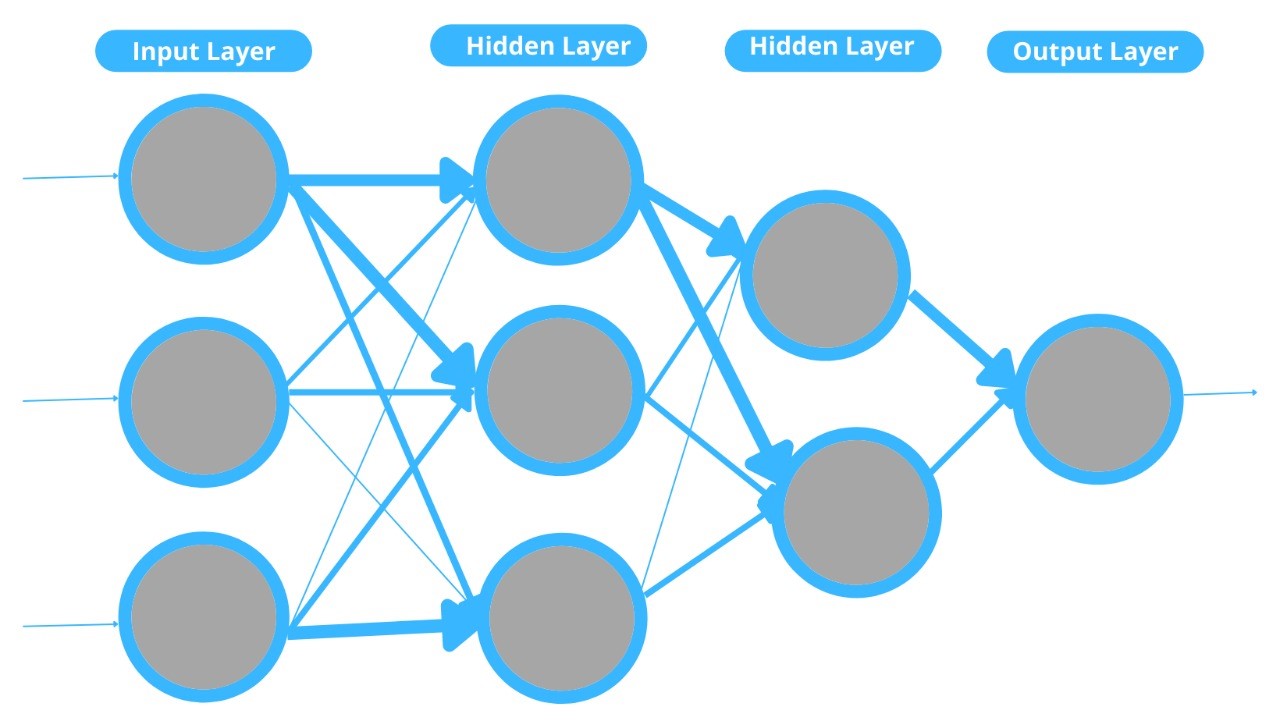
9. What is Neural Network Fundamentals?
The nervous system of human body contains different neurons ad helps to execute the task of whole body. Like this way the Neural Network in deep learning to grasp the pattern of data with the knowledge which it gets from different patterns for the prediction of the output data without the human assistance.
The simplest neural network that has a single neuron performs two functions. One is to weight the sum of all inputs and other is an activation function.
Some neutral networks containing three layers are much more complicated. The three layers are input layer, output layer and the hidden layer.
Input Layer: The input layer of neural network receives input.
Output Layer: The output layer of the neural network provides the prediction as output.
Hidden Layer: There can be many hidden layer between the input and the output layer. The primary hidden layers are used for the detection of the low level pattern and the ultimate layer adds output from the previous layers to discover more patterns.
10. Give some examples when false positive proved important than false negative.
Definition of False Positives: These cases were wrongly identified as an event if they were not. It is also called Type I errors.
Definition of False Negatives: These cases were wrongly identified as non events despite being an event. It is also known as type II errors.
The examples where false positives were important than false negative-
- In medical field:
Suppose a man did not have cancer but the lab report has predicted wrong. It is false positive error. In this case if chemotherapy started, it would be harmful and could cause actual cancer.
2. in e- comers field:
Consider a company thinks to start a campaign where they give $100 gift vouchers for buying $ 10000 worth of items without any minimum purchase conditions. Then the result may be at least 20% profit for items sold above $10000. What if the vouchers are given to the customers who have not buy anything but have been mistakenly marked as those purchased $10000 worth of products. This is the example of false positive error.
11. Discuss about the Exploding Gradients and Vanishing Gradients.
- Exploding Gradients: The exponentially growing error gradients the update to the neural network weight up to a large extent is known as exploding gradients.
- Vanishing Gradients: In the training of RNN, the problem of becoming the slope too tiny is called vanishing gradients. During the training period it provides low rate accuracy and poor performance.
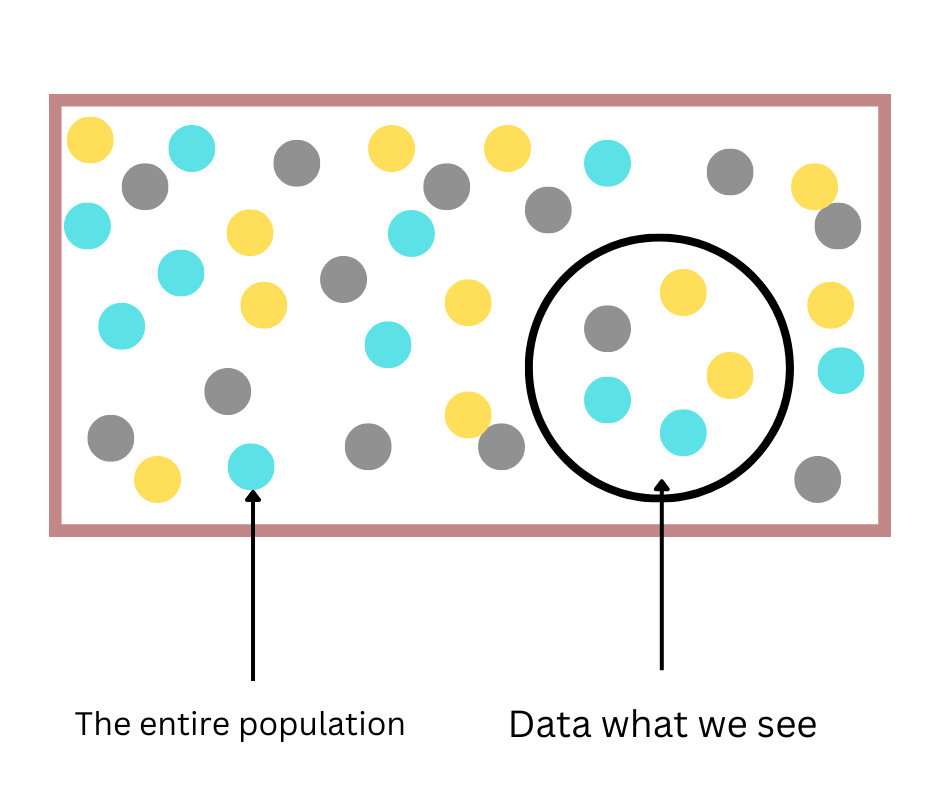
12. What is the necessity of selection bias?
When there is no randomize specifically acquired during the time of picking a data set for analysis, selection bias happens. The bias denotes that the analyzed sample does not present the entire population which is meant for analysis.
- As for the example in the image the selected area can not represent the entire data set. This helps to create the question if we have selected the proper data for the purpose of analysis.
13. Is it favorable to do dimensionality reduction before fitting a support vector model?
If the number of the characteristic is greater than the number of observations then the dimensionality reduction enhances the SVM.
14. What do you think; Python and SQL are enough for Data Science?
Python and SQL are enough for data science but it is better to learn R Programming and SAS. If somebody knows all these three languages then that is more than enough for a proper data science course.
15. What are data science tools?
There are so many tools of data science are available in the market right now. Tensorflow is one of the most famous data science tools now days. Some other famous tools are BigML, SAS, Knime, Pytorch etc.




